Letzte Aktualisierung 15.11.2024
Wenn du PDF-Dateien auf deiner WordPress-Seite hochlädst, landen sie oft in den Suchergebnissen von Google & Co. Das ist nicht immer gewünscht, besonders wenn es sich, zum Beispiel, um PDFs für Newsletter-Abonnenten handelt.
Es gibt mehrere Möglichkeiten, diese Dateien gezielt von der Indexierung auszuschließen:
robots.txt-Datei anpassen
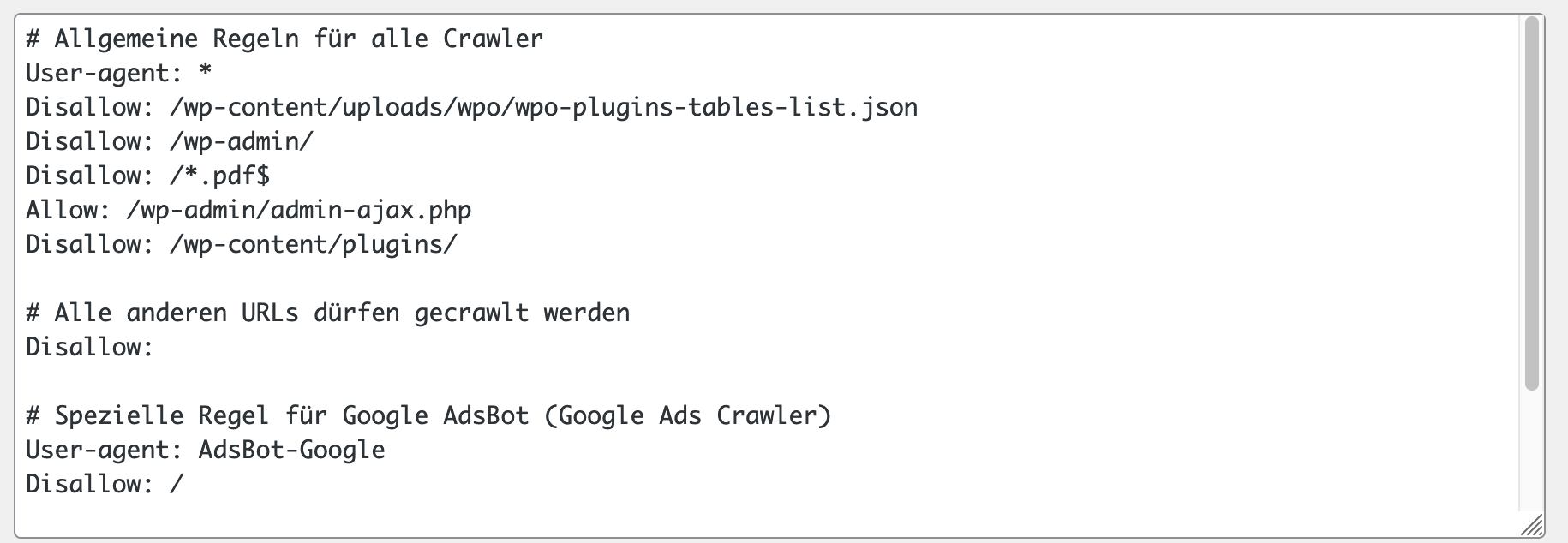
Um alle PDFs von der Indexierung auszuschließen, kannst du in deiner robots.txt folgende Zeile hinzufügen:
User-agent: *
Disallow: /*.pdf$
- User-agent: *:
- Diese Anweisung gilt für alle Suchmaschinen-Crawler (z.B. Googlebot, Bingbot). Das
*ist ein Platzhalter für alle Crawler.
- Diese Anweisung gilt für alle Suchmaschinen-Crawler (z.B. Googlebot, Bingbot). Das
- Disallow: /*.pdf$:
- Diese Anweisung sagt den Crawlern, dass sie alle URLs, die auf
.pdfenden, nicht durchsuchen und indexieren sollen. - Der Teil
/*.pdfbedeutet, dass jede Datei mit der Endung.pdfbetroffen ist. - Das
$-Zeichen stellt sicher, dass die Regel nur auf URLs zutrifft, die genau mit .pdf enden.
- Diese Anweisung sagt den Crawlern, dass sie alle URLs, die auf
Erklärung
- https://meineseite.de/dokument.pdf → Wird nicht indexiert.
- https://meineseite.de/ordner/datei.pdf → Wird nicht indexiert.
- https://meineseite.de/download?file=dokument.pdf → Wird ebenfalls nicht indexiert.
Separaten Ordner für PDF-Dateien nutzen
Lege alle PDF-Dateien, die nur über den Newsletter geteilt werden, in einen eigenen Ordner, z.B. /wp-content/uploads/newsletter-pdfs/.
Füge dann folgende Regel in deine robots.txt ein:
User-agent: *
Disallow: /wp-content/uploads/newsletter-pdfs/
Damit stellst du sicher, dass nur die Dateien in diesem Ordner von Suchmaschinen ignoriert werden.
PDFs per .htaccess von der Indexierung ausschließen
Du kannst den Zugriff auf PDF-Dateien für Suchmaschinen verhindern, indem du HTTP-Header mit der X-Robots-Tag-Anweisung in der .htaccess-Datei hinzufügst. Diese Methode weist den Crawlern an, die Dateien nicht zu indexieren.
# BLOCKIEREN VON PDF-INDEXIERUNG DURCH SUCHMASCHINEN
<IfModule mod_headers.c>
<FilesMatch "\.pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</FilesMatch>
</IfModule>Erklärung der Änderungen:
- <IfModule mod_headers.c>: Überprüft, ob das Modul mod_headers geladen ist, bevor die Header gesetzt werden.
- <FilesMatch „\.pdf$“>: Diese Regel wird auf alle Dateien angewendet, die mit .pdf enden.
- Header set X-Robots-Tag „noindex, nofollow“: Fügt einen HTTP-Header hinzu, der Suchmaschinen-Crawler anweist, diese PDF-Dateien nicht zu indexieren.
Nachdem du diese Änderungen in deine .htaccess eingefügt hast, wird der HTTP-Header X-Robots-Tag für alle PDF-Dateien gesetzt, was dazu führt, dass Suchmaschinen diese nicht indexieren.