Letzte Aktualisierung 07.12.2023
Wenn du feststellst, dass es Seiten deiner Website im Suchmaschinenindex gibt, die keinen klaren Zweck erfüllen oder nicht mehr aktuell sind, solltest du dies nicht außer Acht lassen. Eine fehlerhafte Index-Bereinigung kann deine SEO-Performance negativ beeinflussen. Ob es sich um einzelne unpassende URLs handelt oder ob du eine größere Anzahl unbekannter Seiten in Suchmaschinen findest, es ist wichtig, regelmäßige Kontrollen vorzunehmen, um sicherzugehen, dass die Inhalte in Ordnung sind.
Warum regelmäßige Indexüberprüfungen?
Der Index von Suchmaschinen kann mit einem Kleiderschrank verglichen werden, in dem sich im Verlauf der Zeit einige unerwünschte Dinge ansammeln können. Veraltete oder nicht mehr relevante Seiten können die Ergebnisse negativ beinflussen. Eine gezielte Überprüfung stellt sicher, dass nur hochwertige und inhaltlich relevante Inhalte im Index erhalten bleiben, ähnlich einem Frühjahrsputz für die Website.
Die möglichen Maßnahmen zur Bereinigung des Index
Nachdem du festgestellt hast, dass es Seiten im Index gibt, die du überdenken möchtest, stellt sich die Frage, wie du vorgehen sollst. Ignorieren, löschen oder deindexieren? Ignorieren könnte langfristig zu Problemen führen, Löschen ist eine Möglichkeit, muss aber sorgfältig erfolgen. Das Deindexieren ist eine Lösung, bei der die Seite weiterhin existiert, aber nicht mehr im Index erscheint. Die Wahl der geeigneten Methode hängt von der konkreten Situation ab.
Welche Seiten sollten kontrolliert oder überarbeitet werden?
Die Antwort ist einfach: Entferne bzw. überarbeite alle Seiten aus dem Index, die dort nicht hingehören.
Hier ein paar Beispiele:
- Alte Inhalte (z.B. Blogbeiträge über Plugins, die sich inzwischen weiter entwickelt oder verändert haben) gehören überarbeitet und angepasst
- Verwaiste Seiten (Betrifft Unterseiten die einfach gar intern verlinkt sind und keinerlei Beachtung finden) – werden diese wirklich benötigt?
- Doppelte Inhalte: diese sollten vermieden werden, denn die einzelnen Unterseiten konkurrieren dann untereinander. Besser einen relevanten Beitrag mit gesammelten und relevanten Inhalt, statt zwei Beiträge zum gleichen Thema
- Leere bzw. inhaltslose Beiträge: Suchmaschinen mögen Artikel/Beiträge mit Relevanz, wo der Leser Fragen auf seine Antworten findet. Allerdings sollten diese Beiträge auch zum Thema der Webseite passen.
Hilfreich kann auch immer die Frage sein, ist der Beitrag so gut, dass sie im Index zu finden sein soll? Nach diesem Schema sollten alle Unterseiten betrachtet werden. Und nach dieser Kontrolle wird dann entschieden, wie weiter vorgegangen wird.
Welche Methoden kannst Du einsetzen?
Es können verschiedene Schritte ergriffen werden, darunter das Setzen bestimmter Seiten auf „noindex“, die Implementierung von „Kanonisierung“ oder die Löschung von Seiten. Zudem spielt im Rahmen der Crawling-Steuerung eine robots.txt-Sperrung eine Rolle.
Die Entscheidung, welche Methode am besten geeignet ist, erfordert eine sorgfältige Analyse. Es ist wichtig, eine blinde Desindexierung von Inhalten zu vermeiden. Denn nur so kannst Du sicherzustellen, dass nur unwichtige oder überholte Inhalte entfernt werden.
- Website ist mit www und ohne www aufrufbar: Setze pasende Redirects
- Archivseiten / Tag Seiten in WordPress: Datumarchiv, Autorarchiv und Tagseiten sollten auf noindex stehen
- andere Seiten: Datenschutzerklärung, Formulare & und die 404 Seite gehören auch nicht in den Index und sollten auf noindex stehen
- Medienseiten & Anhänge: sollten auch auf noindex stehen
- Suchergebnisse auf der eigenen Seite: gehören nicht in den Index
- Löschen und 301-Weiterleitungen unnötiger und veralteter Beiträge (die du nicht mehr überarbeiten möchtest)
So überprüfst du den Indexierungsstatus deiner Seite:
Um den Indexierungsstatus deiner Webseite zu überprüfen, gibt es mehrere Methoden. Hier sind einige gängige Ansätze:
- Google Search Console: Nutze die Google Search Console, um detaillierte Informationen über den Indexierungsstatus deiner Seiten zu erhalten. Hier kannst du den Indexierungsbericht einsehen und gegebenenfalls Maßnahmen ergreifen.
- Site:Suchanfrage in der Suchmaschine: Gib „site:deine-webseite.de“ in die Suchmaschine ein. Die Ergebnisse zeigen dir, welche Seiten von deiner Domain im Index aufgenommen wurden.
- Crawling-Tools: Verwende Crawling-Tools wie Screaming Frog oder änliches, um einen umfassenden Überblick über den Indexierungsstatus zu erhalten.
Google Search Console
Über die Search Console erhältst Du einen guten Überblick über die indexierten Seiten. Dazu einfach einloggen und über den Menüpunkt: Indexierung/Seiten nachschauen.
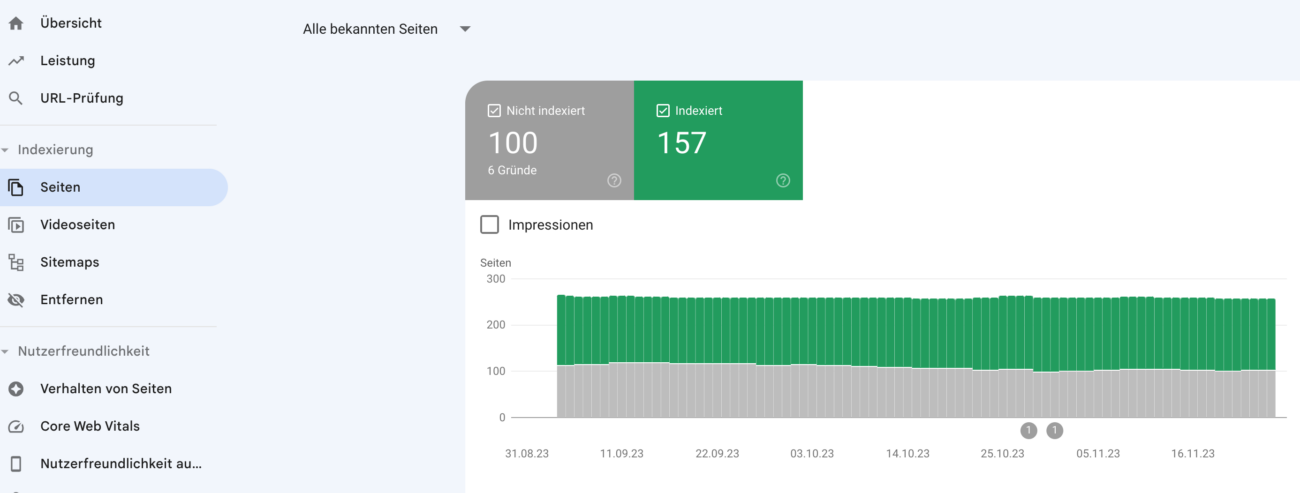
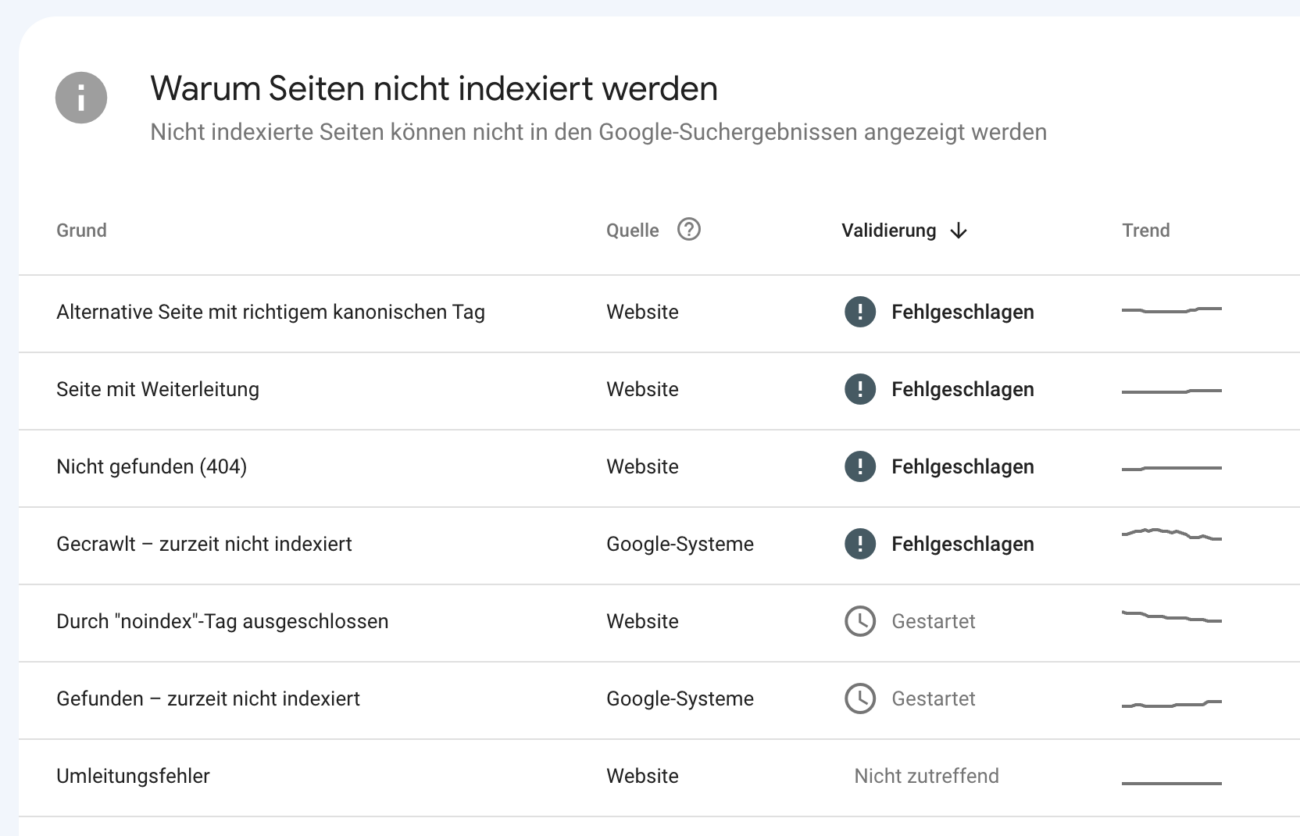
Im Bericht zur Indexierung in der Google Search Console (GSC) erhältst du Einsicht in die Gründe, warum bestimmte Seiten nicht indexiert sind. Analysiere diese Seiten sorgfältig und untersuche die zugrunde liegenden Ursachen.
NoIndex und Canonical Tags richtig einsetzen
Im HTML-Header einer Webseite kannst du das Meta Robots Tag „noindex“ platzieren, um das Verhalten von Suchmaschinenrobotern auf dieser Seite zu steuern. Die Verwendung von „noindex“ bewirkt, dass die Seite nicht im Suchmaschinenindex erscheint. Wenn Du WordPress verwendest, kannst Du diese Einstellungen über Yoast oder RankMath vornehmen.
Bei welchen Seiten bietet sich noindex an?
- Dankeseiten nach Formulareinreichungen
- Duplizierte Inhalte
- Interne Suchergebnisseiten
- Archivseiten
- Test- oder Entwicklungsseiten
- Nutzerlogin-Seiten: Seiten, die nur für eingeloggte Benutzer relevant sind, können auf „noindex“ gesetzt werden, um sicherzustellen, dass sie nicht in den Suchergebnissen erscheinen
- Bestätigungsseiten
- Datenschutzerklärung
Die Canonical Tags sind ein wichtiger Bestandteil der On-Page-Optimierung und tragen dazu bei, die Sichtbarkeit einer Website in den Suchergebnissen zu steigern, indem sie Probleme mit Duplicate Content reduzieren.
So setzt Du sie richtig ein:
- Identifiziere Duplikate: Finde verschiedene URLs mit ähnlichem Inhalt.
- Wähle die kanonische URL: Entscheide, welche URL bevorzugt werden soll.
- Füge das Canonical-Tag hinzu: Setze das <link rel=“canonical“> Tag in den <head>-Bereich der kanonischen Seite: html <link rel=“canonical“ href=“https://www.deine-webseite.de/deine-kanonische-seite“>
- Teste die Umsetzung: Überprüfe mit Tools wie der Google Search Console die korrekte Erkennung der Canonical-Tags.
- Achte auf Konsistenz: Stelle sicher, dass Canonical-Tags konsistent und korrekt eingesetzt werden.
Der Einfluss von robots.txt: Steuere das Crawling-Verhalten von Suchmaschinen auf deiner Website
Die robots.txt-Datei besteht aus spezifischen Anweisungen, die von Suchmaschinenrobotern interpretiert werden, um den Crawling-Prozess zu steuern. Sie ermöglicht Dir, bestimmte Seiten oder Verzeichnisse vor dem Zugriff durch Suchmaschinen zu schützen oder zu erlauben.
Ein einfaches Beispiel für eine robots.txt-Datei könnte so aussehen:
User-agent: * Disallow: /geheimes-verzeichnis/ Allow: /oeffentlicher-bereich/
In diesem Beispiel wird allen Suchmaschinenrobotern („User-agent: *“) untersagt, das Verzeichnis „/geheimes-verzeichnis/“ zu crawlen, während der Zugriff auf den „/oeffentlicher-bereich/“ erlaubt ist.
Die Überwachung des Crawlings ist eine sinnvolle Maßnahme zur Vermeidung des Crawlens großer Mengen irrelevanter Seiten und zur Sicherstellung einer effizienten Nutzung der Crawling-Ressourcen.
Beispiel gefällig?
Angenommen, du betreibst einen Onlineshop für Elektronikartikel. Jedes Produkt hat eine spezifische Seite, die für verschiedene Länder angepasst wurde.
Die URLs sehen beispielsweise so aus:
- Produkt A für die USA: www.deinshop.com/en-us/produkt-a/
- Produkt A für Deutschland: www.deinshop.com/de/produkt-a/
- Produkt A für Frankreich: www.deinshop.com/fr/produkt-a/
Die Internationalisierung Deines Shops hat jedoch dazu geführt, dass sich die Anzahl der URLs exponentiell vermehrt hat. Dies könnte zu einem übermäßigen Crawling führen, insbesondere wenn bestimmte Versionen nicht so relevant für die Suchergebnisse sind.
Wenn Du feststellst, dass das Crawlen außer Kontrolle gerät und es zu Performance-Problemen kommt, könntest du die robots.txt-Datei nutzen, um bestimmte Versionen zu blockieren.
User-agent: * Disallow: /en-us/
Durch diese Anweisung verhinderst du, dass der Crawler die Seiten für den US-Markt crawlt. Das sorgt für eine gezieltere Nutzung der Crawling-Ressourcen und kann die Leistung der Website stabilisieren. Triff diese Entscheidung aber sehr sorgfältig, um sicherzustellen, dass wichtige Seiten weiterhin indexiert werden.
Wichtiges zum Schluss
Die Pflege und Bereinigung des Suchmaschinenindex ist ein wichtiger Schritt für eine erfolgreiche SEO-Strategie. Ziel ist es, veraltete, unrelevante, qualitativ minderwertige und doppelte Inhalte zu entfernen, um die Qualität der Suchergebnisse zu verbessern.
Es ist deshalb unerlässlich, alle irrelevanten Seiten aus dem Index zu beseitigen. Die Wahl der Methode zur Bereinigung hängt von der individuellen Situation ab. So kann es sein, dass es besser ist, Seiten zu löschen, 301-Weiterleitungen einzurichten, noindex-Tags zu setzen oder Canonical-Tags zu verwenden, oder dass das eigentliche Problem im Crawling liegt und eine robots.txt-Sperre erforderlich ist.
Wenn Du dabei Hilfe benötigst, weil Dir die Zeit oder das nötige Know How fehlt, schreib uns gerne an. Wir sind für Dich da.